
I would like to share with you an example that totally changed my perception of how I look at automated checking, whether it is unit or integration.
I am programming a lot in .NET. The language I use is C#. The code written in the end is packaged in a .dll or .exe file. If you will look at the content of this file you will not see C# code. You will see MSIL code which is like an assembly language. This MSIL at runtime is translated into processor code.
Here is a C# code, it is taken from the book CLR via C#:

This code is a little bit weird. I admit that it is an extreme example. But it helps me communicate what I want. Let’s suppose that we covered, so to speak, this code with unit checks done ok. Lets also suppose that the code review was quite rigorous and carefully done.
I have some questions:
- Is it just a line of code?
- How many memory allocation problems can occur?
Let’s change the perspective. What you see bellow is the MSIL code generated from the C# code you see above:

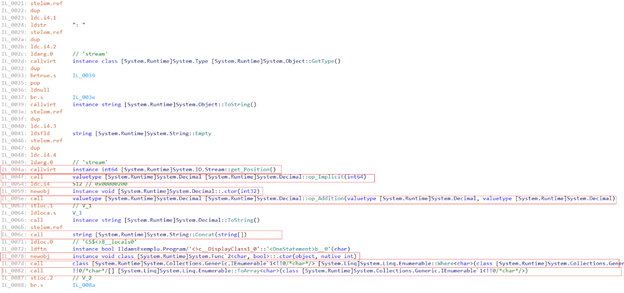
Side Note: By the way, this MSIL code generated from a .Net Core code. Do you think it’s very different from .NET 4.8 code? The answer is no. I ask this because there are people whose CVs will not be accepted because they have not worked with .NET Core, but have experience with .NET. For me is an indication that we focus too much on shallow things.
All those things you see marked with red indicate a place where memory allocation problems might occur.
From my experience not a lot of .NET programmer’s look at the MSIL code. But let’s think about unit checks. You see, what you do know isn’t canceled, it’s okay. But now don’t you think about code coverage in a different way? It’s something else, isn’t it?
Note: For Java we have Java bytecode
This perspective helped me, in this context, to understand that I can think, for example, of memory corruption coverage. Which is just another type of coverage. But I wrote this post to try to answer another question which is: What bugs you aren’t finding while you automate checks? For me, as a programmer, it is very clear that I focus on a certain direction when developing an automated check and nothing else. But focusing on a certain direction means ignoring other dimensions. In the example above I would have ignored memory problems or what MSIL code is being generated and the kind of instructions which will actually be run.
This is a three-part series:
Automation in testing – Part 3 – What bugs you aren’t finding while you automate checks?
Thank you Johanna Rothman
Marius, you are welcome!!